Как важно писать хороший код
Мне приходится очень много читать код. Это и open source, и всяческие фреймворки, и код enterprise приложений. Именно о последних я хотел бы сегодня поговорить.
Большая часть кода enterprise приложений - отстой. Приложения глючат и тормозят, их сложно тестировать, постоянно проблемы с развертыванием и обновлением. Это как бы никого не удивляет.
Но удивляют люди, написавшие отстойный код. Эти люди, с немалым опытом, знают несколько языков, прочитали много книг, знают ООП, SOLID, рефакторинг, паттерны и другие малопонятные слова. То есть примерно такие, как многие из вас, читающих этот пост.
Теория разбитых окон
В 1969 году был проведен эксперимент. В ходе эксперимента две одинаковые машины были оставлены в двух местах – в благополучном университетском городке и неблагополучном районе крупного города. Не удивительно что в неблагополучном месте машина простояла всего пару дней и была выпотрошена, а в благополучном машина простояла нетронутой неделю. Но как только в уцелевшей машине разбили стекло, жители этого самого благополучного городка за несколько часов разобрали её на детали и перевернули вверх дном.
В последствии ученые назвали это явление “Теорией разбитых окон”. Согласно теории, любое проявление беспорядка или нарушение норм провоцирует людей также забыть о правилах. Теория получила несколько экспериментальных подтверждений и её можно считать вполне достоверной.
Есть также и обратный эффект. Поддержание порядка приводит к тому, что окружающие также поддерживают порядок.
Как это влияет на код
В enterprise разработке прессинг сроков и неопределенности требований бывает настолько высок, что кажется сделать “быстро и грязно” – гораздо лучший вариант, чем сделать правильно. Моментально подход “быстро и грязно” начинает распространяться по всему приложению, как путем clipboard inheritance (aka copy-paste), так и за счет эффекта разбитых окон.
Еще один фактор влияющий на качество кода – сложность и несовершенство платформ и фреймворков, используемых в разработке. Из-за этого в коде часто появляются хаки и нелепые workaround_ы. Со временем начинает казаться что эти хаки и есть хороший код. Даже когда проблемы фреймворков исправляют, люди продолжают использовать хаки. Кстати эти хаки со временем могут попадать в интернет через форумы, блоги или pastebin и распространяться далеко за пределы одного приложения.
Вы можете сказать, что качество кода не влияет на качество приложения. Увы, еще как влияет. Программисты допускают ошибки. Чем более плохой код, тем сложнее эти ошибки найти и исправить так, чтобы не создать новых. Прессинг сроков и сложности, скорее всего, не даст написать хороший код и появится еще один хак.
В open source и продуктовой разработе такое встречается реже. Там больше следят за качеством и меньше прессинг сроков.
Код пишется для людей
Часто программисты забывают что код программ пишется в первую очередь для людей. Даже если вы пишите программу в одиночку, то посмотрев на нее через месяц, вы не вспомните почему написали тот или иной кусок кода и за что он отвечает.
Хороший код должен, в первую очередь, очень ясно выражать намерения. К сожалению “быстрые и грязные” способы разработки бьют в первую очередь по понимаемости кода. Улучшение кода осознанно откладывается до лучших времен, когда будет пауза чтобы провести рефакторинг. Те самые лучшие времена никогда не наступают, а код начинают читать и дорабатывать сразу же после попадания в source control.
Даже если вы полностью довольны свои кодом (в большинстве случаев программисты свои кодом довольны), то подумайте о том как будет ваш код читать другой человек (в большинстве случаев программисты недовольны чужим кодом).
Приверженность качеству
Единственный способ добиться высокой продуктивности и эффективности – писать хороший код сразу. Единственный инструмент повышения качества кода – вы сами. Если вы не стремитесь всегда делать хороший код, то вам не помогут ни тесты, ни инструменты статического анализа. Даже ревью других программистов не поможет. Код всегда можно сделать настолько запутанным, что в нем невозможно будет найти ошибку при чтении, при этом сделать вид, что код очень важен и никто не возьмется его переписать.
В первую очередь необходимо думать о структуре и именовании. Код с зашифрованными идентификаторами и малопонятным потоком исполнения скорее всего будет содержать ошибки. Не допускайте такого кода, это гораздо дешевле, чем исправлять ошибки.
Ясно выражайте намерения в своем коде, сводите к минимуму неочевидные неявные аспекты. Не надо стремиться сделать код максимально лаконичным, стремитесь сделать его максимально понятным.
Если вам приходится править код, то не создавайте хаков. Потратьте немного времени, напишите нормально. Сэкономите на поддержке. Если же код совсем плохой, был сделан “быстро и грязно” и оброс хаками, то просто выкиньте его и перепишите. Только не надо пытаться переписать все. Учитывайте продуктивность: программист пишет 40-60 отлаженных строк кода в день в нормальном темпе и 120-200 в ускоренном (высокая концентрация, четкая цель, понятно что делать).
Если вы сами пишете “быстро и грязно”, например прототип для уточнения требований, то выкиньте код и перепишите нормально сразу после того, как ваш код сделает свое дело.
Если вы скопировали часть кода из другого места или, не дай бог, из интернета, то разберитесь как он работает, прежде чем заливать изменения в source control. Вообще не используйте непонятные вас фрагменты кода.
Всегда поддерживайте чистоту и порядок в вашем коде, пользуйтесь инструментами, которые помогают вам это делать. Не будете этого делать – код очень быстро превратится в помойку. Собирайте статистику по плотности проблем в коде, это поможет вам лучше понять, как писать хороший код.
Перечитывайте свой код. Проводите рефакторинг постоянно в процессе написания. Помните, что рефакторинг “потом” никогда не наступает.
Думайте о том, какой код вы хотите написать, до того как начать его писать. Само написание кода – настолько поглощающий процесс, что думать о качестве некогда. Состояние потока – это состояние свободы самовыражения. Необходимо заранее ограничить самовыражение, чтобы код получился хорошим.
Экономика качества кода
Все знакомы с кривой стоимости ошибки: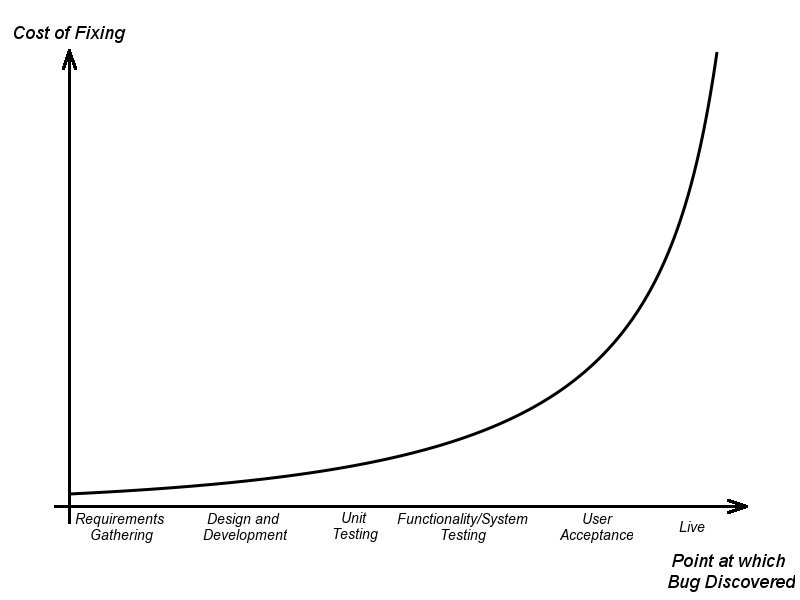
Ошибка найденная и устраненная на этапе кодирования в 10 раз дешевле, чем ошибка найденная при тестировании и в 100 раз дешевле ошибки, найденной в production. В истории есть реальные примеры ошибок, исправление которых обошлось в десятки тысяч долларов.
Поэтому очень важно устранять ошибки на этапе разработки, причем усилиями самих разработчиков.
На последок
Не путайте хороший и идеальный код. Идеального кода не существует, нет смысла заниматься бесконечным улучшением в стремлении к идеалу. Хороший код – это код который читаем, понятен, решает задачу, правильно структурирован и не содержит ошибок. Писать хороший код не просто ваша цель, это ваша обязанность.
Host-Named SiteCollections
В SharePoint 2013 без большого шума появилась новая best-practice, рекомендующая использовать так называемые Host-Named SiteCollection (HNSC). Как обычно это вызывает множество вопросов, на которые я попробую ответить.
Краткий экскурс в историю
Во времена x86 процессоров максимальный объем адресного пространства, которое могло занимать приложение – 2гб. Поэтому для масштабирования был выбран подход, когда вся ферма SharePoint разбивается на несколько “веб-приложений”, каждое из которых представляет один или несколько сайтов на IIS. Тем не менее создание сайтов на IIS – дорогое удовольствие. Каждый сайт запускает как минимум один процесс w3wp, который загружает сборки SharePoint и съедает немало памяти. Поэтому даже придумали лимит веб-приложений.
Еще один фактор, который подталкивает плодить веб-приложения в SharePoint – безопасность. Каждое веб-приложение содержит множество коллекций сайтов, все имеют общий hostname. Это значит что javascript из одной коллекции сайтов может обращаться к ресурсам другой коллекции с правами текущего пользователя (Cross-Site Scripting). А для добавления JavaScript достаточно иметь права хотя бы на одно узле.
Таким образом даже появление x64 версий SharePoint не изменило картину – все использовали веб-приложения и отдельные сайты IIS.
HNSC существовали еще в SharePoint 2003 (только назывались не так). Они позволяли иметь коллекции сайтов с разными hostname в рамках одного веб-приложения SharePoint. Но из-за ограничений и сложностей использования не прижились. В SharePoint 2010 произошло улучшение HNSC в первую очередь для Office 365.
В SharePoint 2013 снова улучшили HNSC и появились некоторые возможности\особенности платформы, которые делают HNSC лучшим выбором.
Для чего нужны HNSC
Обязательно нужно запомнить (ибо понять это сложно): Host-Named SiteCollection это альтернатива веб-приложениям, а не обычным коллекциям сайтов. При использовании HNSC обычные коллекции сайтов, официально называемые Path-Based SiteCollection, все так же доступны.
Как я писал выше, HNSC позволяют создавать коллекции сайтов с разными hostname в рамках одного веб-приложения. В SharePoint 2013 HNSC также научлись поддерживать несколько hostname в разных зонах и SSL Termination и разные режимы аутентификации на основе зон.
С точки зрения API обычные коллекции сайтов не отличаются от HNSC. Важно только помнить что SPSite.Url может не совпадать ни с одним из Url в объекте SPSite.WebApplication.
Применять HNSC нужно по трем причинам:
- Экономия ресурсов.
Все HNSC живут в одном веб-приложении, следовательно в одном процессе w3wp. Это означает, что загружена только одна копия сборок SharePoint, что уменьшает оверхед на пару сотен мегабайт на процесс. - Совместимость с apps.
Для того чтобы работали apps нужен wildcard-сайт, который принимает запросы на любой hostname, потому что AppWeb создается с уникальным hostname.
Но AppWeb это все еще сайт SharePoint, поэтому требуется загрузка всех объектов SharePoint в процесс веб-сайта, обсуживающего apps.
Если все коллекции сайтов находятся в одном сайте IIS, то это также уменьшает оверхед и упрощает, в итоге, настройку IIS. - Новые фичи SharePoint 2013.
В SharePoint 2013 появилась фича Request Management, позволяющая управлять WFE. Request Management позволяет задать какой WFE будет обрабатывать запросы какого типа. Конфигурация может быть динамической, учитывающей состояние сервера (нагрузка, ресурсы итд). Microsoft говорит что эта фича тестировалась только с HNSC и в будущем новые фичи будут работать в первую очередь с HNSC.
Недостатки HNSC
Увы использовать HNSC не так просто. Central administration сайт не умеет создавать HNSC, поэтому всю работу надо будет делать в PowerShell.
Тем не менее для любителей тикать мышкой есть проект на codeplex: https://hnsc.codeplex.com/https://hnsc.codeplex.com/.
Кроме того HNSC обеспечивают гораздо меньшую изоляцию ресурсов сервера, по сравнению с веб-приложениями. Все HNSC будут иметь общие настройки веб-приложения, такие как throttling, настройки корзины, настройки безопасности и аутентификации, общие managed paths, итд. У всех HNSC будет общий web.config и общий app pool. Это значит что установка приложений будет затрагивать все HNSC.
Как создавать HNSC
Я не буду писать множество PowerShell команд для создания и настройки HNSC. На MSDN есть прекрасный гайд по HNSC (даже с достойным переводом на русский язык), который описывает разные топологии, а также процесс перехода от Path-based sitecollections к HNSC.
Ссылка на гайд: http://technet.microsoft.com/ru-ru/library/cc424952.aspx.
Дополнительные материалы для тех, кто решит использовать HNSC:
- http://blogs.msdn.com/b/kaevans/archive/2012/03/27/what-every-sharepoint-admin-needs-to-know-about-host-named-site-collections.aspx
- http://blogs.msdn.com/b/russmax/archive/2013/10/31/guide-to-sharepoint-2013-host-name-site-collections.aspx
Заключение
Для правильного развертывания SharePoint 2013 уже недостаточно просто воспользоваться визардом. Теперь требуется планирование, анализ требований, вариантов решений которые предлагает SharePoint и оценка всех tradeoffs. А это требует как минимум понимания возможностей SharePoint.
Как работает развертывание решений в SharePoint
Развертывание решений SharePoint - это нескончаемый источник ошибок, слухов и легенд. Причина этому простая – процесс деплоймента (и отката) решений практически никак не документирован. Начиная с SharePoint 2010 ситуация усложнилась появлением sandbox solutions и механизмом апгрейда фич.
Общая схема

(взято отсюда)
По пунктам:
- WSP пакет сначала попадает в конфигурационную базу
- При развертывании файлы из пакета попадают на компьютеры фермы, это касается фич, сборок и файлов приложения.
- При активации фич на основе манифеста в контентной базе создаются записи, которые ссылаются на файлы на диске.
Такая схема была изобретена в ранних версиях SharePoint, чтобы экономить место в базе, если одна и та же функциональность используется на многих сайтах. Кроме того так очень удобно обновлять, достаточно развернуть новую версию пакета и все сайты получат изменения.
На практике такая схема работает плохо...
Проблемы
Когда артефакты (файлы, поля, типы контента, списки) создаются таким образом, как описано выше, они называются ghosted (в SharePoint 2007) или uncustomized (с SharePoint 2010).
Проблемы начинаются тогда, когда файлы\поля\типы\списки изменяются. Когда это происходит в базу записывается схема (XML определение) или сам обновленный файл, а связь с файлом на диске теряется. Это состояние называется unghosted или customized. Дальнейшее обновление путем обновления файлов на диске уже перестает работать.
Ситуация усугубляется тем, что деактивация фич не удаляет списки и файлы и не удаляет типы контента и поля, на которые ссылаются списки. Повторная активация фич, при наличии артефактов в контентной базе, работает совершенно непредсказуемо.
Это кстати одна из базовых ошибок дизайна feature framework, из-за которой весь деплоймент стал невероятно сложным. Если бы деактивация фич удаляла все артефакты и при удалении решения фичи деактивировались, то делать решения стало бы гораздо легче. Но в 2007 году об этом не подумали и сделали выбор в пользу сохранения данных, а не контролируемости развертывания.
Можно, конечно, все артефакты создавать с помощью XML, избегая кода, который вызывает кастомизацию. Но далеко не все решения можно делать таким образом. Многие вещи, вроде таксономии, audience targeting и metadata mavigation в XML описать очень сложно. Но самое главное, что кастомизация может быть вызвана пользователем. А если возможность кастомизации заблокировать, то теряется гибкость, которую дает SharePoint.
Еще одна проблема связана со списками и шаблонами (определениями) списков. Если список создан по шаблону и не кастомизирован, но шаблон отсутствует на диске, то появляется множество непонятных ошибок при использовании API и некоторых стандартных функций.
Из-за этих проблем многие полностью отказались от развертывания артефактов с помощью XML определений и начали делать создание артефактов с помощью кода. Этот подход гораздо более многословен и повышает вероятность ошибок, но при этом дает контролируемость процесса при создании, и самое важное, при обновлении артефактов.
SharePoint 2010 и Sandbox
Естественно в Microsoft обо всех этих проблемах знали и в 2010 версии сделали некоторые изменения, которые должны были улучшить ситуацию.
Первое изменение – добавление флагов Overwrite в определениях полей и типов контента. С этим флагом поля и типы при активации фичи записываются в контентную базу, без создания привязки к файлам на диске. Кроме того стала возможна повторная активация фич при наличии артефактов в контентной базе данных. Это частично решает проблему, но только частично, так как проблема со списками, созданными из шаблонов, не решается.
Второе изменение – добавление возможности апгрейда фич. Теперь можно не удалять решение и не переактивировать фичи для получения новой функциональности.
Третье изменение – появление Sandbox решений, которые не используют файлы в файловой системе и создают все артефакты сразу в контентной базе. При этом откат Sandbox решения вызывает деактивацию всех фич, а для FullTrust такого не происходит.
Казалось бы теперь можно сделать то что нужно, используя правильные возможности. Но вышла еще одна промашка – все изменения почти никак не документированы и процесс развертывания стал еще более непредсказуемый и вообще сложилась ситуация когда никто не знает как делать правильно.
В SharePoint 2013 кстати тоже произошли небольшие улучшения, но снова почти не документированные.
Что же делать
Вариант первый – делать все кодом. К сожалению кода получается очень много и писать его очень муторно. Некоторые вещи сделать кодом сложно, некоторые вообще невозможно.
Вариант второй – делать развертывание в XML, не деактивировать фичи (особенно если ведет к потерям данных или к нарушению работоспособности), не откатывать решение, использовать feature upgrade. Это тоже требует написания кода, но в гораздо меньшем объеме.
Кстати использовать активацию фич для поставки функционала пользователю – тоже не лучший вариант. Гораздо лучше:
- Создание сайтов по шаблону.
- Создание списков по шаблону.
- Дополнительными пунктами в меню администрирования (для сайтов, списков, типов контента).
- Расширением существующего функционала.
Сам фичи лучше всего делать скрытыми, активировать их автоматически при развертывании решения или скриптом установки.
Если же делаете фичу видимой, то нужно всегда тестировать возможность её многократной активации\деактивации, в том числе на разных сайтах и коллекциях сайтов.
Заключение
Если вы работаете с SharePoint, то вам в любом случае необходимо знать как работает развертывание артефактов. Узнать это можно типовым для SharePoint способом – ковырянием сборок в ILSpy или Reflector. Большую часть из того, что я описал в этом посте я узнал именно из сборки Microsoft.SharePoint.
В следующий раз расскажу как пользоваться работает feature upgrade и как быстро создавать решения в SharePoint.
SPTypeScript Release 1.3
TypeScript неумолимо приближается к релизу, недавно вышла версия 0.9.5.
Вместе с этим мы продолжаем развивать наши определения типов JavaScript Object Model в SharePoint, чтобы вам было комфортно писать клиентский код для решений и приложений SharePoint.
На сайте проекта http://sptypescript.codeplex.com/ опубликован новый релиз, в который вошли:
- Определения для Chrome Control для apps.
- Определения для SPClientPeoplePicker для создания кастомных форм с контролом выбора людей.
- Полные определения типов для пространств имен SP.Publishing и SP.DocumentManagement из файлов sp.publishing.js и sp.documentManagement.js соответственно. Они вам очень пригодятся для ECM\WCM сценариев.
- Reputation object model – для социальных приложений.
- Множество примеров и мелкие улучшения существующих определений.
Ссылка на релиз - http://sptypescript.codeplex.com/releases/view/115896
Также последнюю версию определений можно получить с помощью NuGet -http://www.nuget.org/packages/sharepoint.TypeScript.DefinitelyTyped/
Как использовать TypeScript для приложений SharePoint
Для начала установите последнюю версию TypeScript (0.9.5).
Создаете новый App для SharePoint в VisualStudio 2013

Теперь самое неприятное – надо поправить .csproj файл, чтобы включить компиляцию TypeScript. Для этого надо:
- В контекстном меню проекта нажать Unload Project
- На выгруженном проекте нажать Edit
- В самом конце, перед закрывающим тегом Project надо добавить одну строчку:
<Import Project="$(MSBuildExtensionsPath32)\Microsoft\VisualStudio\v$(VisualStudioVersion)\TypeScript\Microsoft.TypeScript.targets" />
- На выгруженном проекте нажать Reload Project
- Верить что к релизу не придется исполнять эти танцы с бубном...
После этого надо выставить настройки проекта в свойствах проекта
Далее переименовываете App.js в _App.js. Удалять не надо, он еще пригодится.

Добавляете App.ts файл

Добавляете дефинишены для SharePoint и JQuery с помощью NuGet

Копируете содержимое _App.js в App.ts и удаляете _App.js и сразу получаете типизацию в .ts файле. Можно также сделать небольшой рефакторинг в стандартном шаблоне, чтобы максимально использовать типизацию:

Последний штрих – скомпилировать проект и добавить сгенерированные App.js и App.js.map в решение.

Теперь можно запускать приложение и будет работать отладка в .ts файле

Планы на будущее
Сейчас дефинишенами покрыто почти все API для которого можно хоть как-то найти документацию. К релизу TypeScript 1.0 мы выпустим версию SPTypeScript 1.5 (или 2.0). Если есть какой-то API SharePoint, для которого вы хотите видеть дефинишены в нашем проекте, пишите на CodePlex в раздел Discussions - http://sptypescript.codeplex.com/discussions.
Будем рады любому фидбеку.
SharePoint Day: 14 декабря, Москва
14 декабря 2013 года состоится встреча встреча Russinan SharePoint User Group (RUSUG) в новом формате. Встреча будет проходить в субботу в офисе Microsoft в Крылатском. Вместо обычных двух докладов будет целых шесть в два потока. Начало в 10.00. Как всегда будет вестись трансляция для тех, кто не сможет приехать.
Внимание. Регистрация обязательна. Зарегистрироваться можно по ссылке http://rusug.timepad.ru/event/95901/. Выбирайте правильный тип регистрации.
Программа мероприятия:
| Время / Поток | Поток 1 | Поток 2 |
| 10:00 - 11:00 | Все что вы хотели узнать про Office Web Apps Server 2013, но боялись спросить Илья Бойко | Yammer для разработчика Михаил Бондаревский |
| Перерыв | ||
| 11:15 - 12:15 | Как улучшить качество решений для SharePoint. Пособие для владельцев ферм и разработчиков Стас Выщепан (это я) | Планирование в Excel + PowerShell = Готовый портал SharePoint 2013 Сергей Слукин |
| Перерыв | ||
| 12:30 - 13:30 | SharePoint 2013. Поиск в корпоративной среде Виталий Жуков | Новая прадигма брендинга в SharePoint 2013 Александр Романов |
| Перерыв | ||
| 13:45 - 14:30 | Круглый стол | |
Страница мероприятия на facebook - https://www.facebook.com/events/183651665162179/
Описания докладов можно найти по ссылке - http://www.gotdotnet.ru/blogs/sharepoint/14107/
Присоединяйтесь все желающие, до встречи в субботу.
PS. Формат субботних встреч по SharePoint (SPSaturday) очень популярен в мире - https://www.google.ru/#q=spsaturday. Надеюсь и у нас приживется.